Frankreich KNALLT JETZT sein nächstes KI-Schwergewicht raus: Mistral Small 4 ist da – und es vereint drei früher getrennte Modelle in einem einzigen, vollständig Open-Source-Release. So einfach kannst du Reasoning, Vision und Coding selbst hosten.
HAMMER: Drei Modelle in einem Container
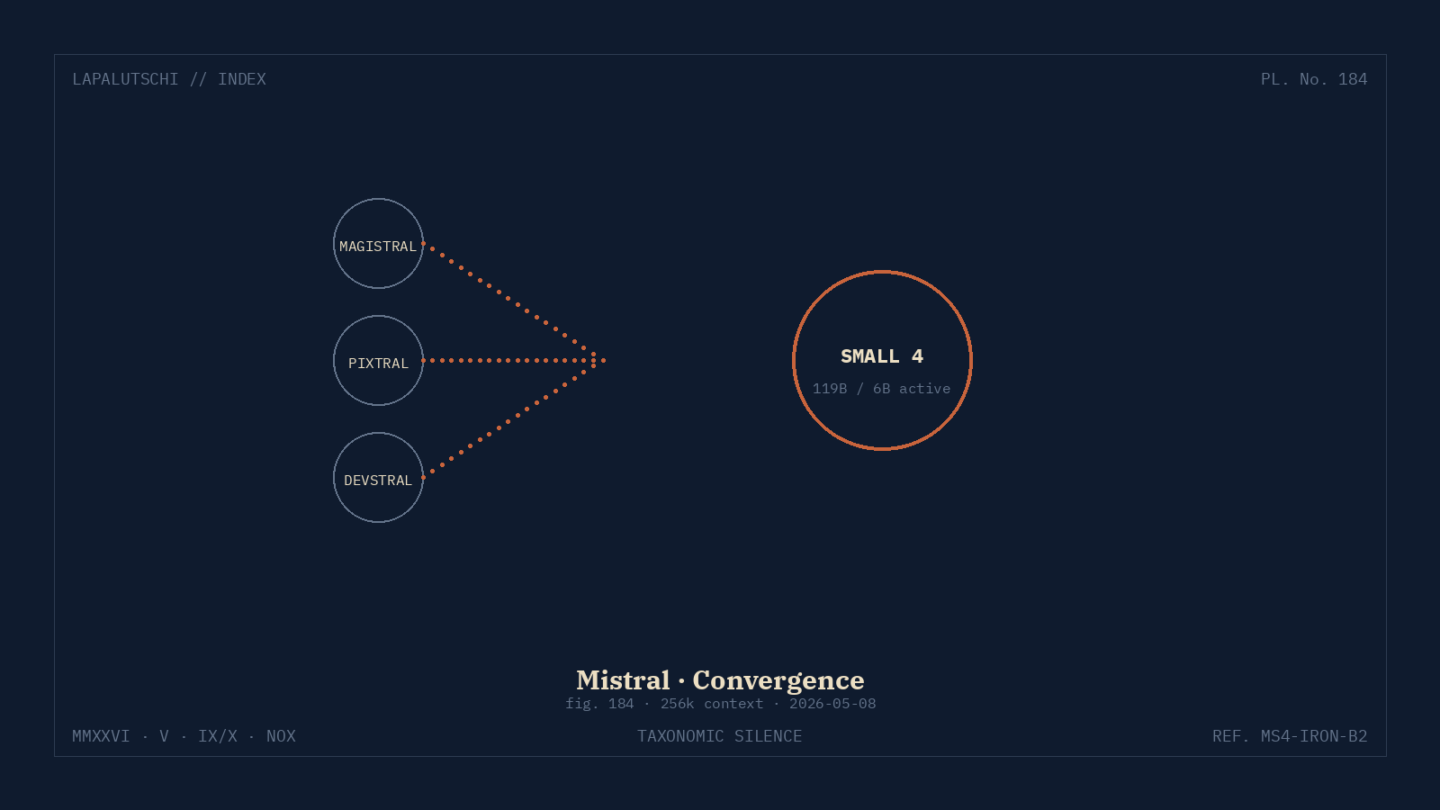
Bisher musstest du dich entscheiden: Magistral fürs harte Denken, Pixtral für Bilder, Devstral fürs Programmieren. Mit Small 4 räumt Mistral diese Trennung weg – ein einziges Mixture-of-Experts-Modell macht jetzt alles. Für dich heißt das: ein Container, ein Endpoint, drei Skills.
SO STARK schlägt das Ding
Mistral nennt 119 Milliarden Parameter total und nur 6 Milliarden aktive Parameter pro Token. Heißt: groß im Wissen, schlank in der Inferenz. In den eigenen Benchmarks knackt Small 4 sowohl Magistral als auch Pixtral und liegt beim Coding ein paar Punkte unter Devstral – aber dafür bekommt es jetzt eben alles aus einer Hand.
MEGA-CONTEXT: 256.000 Tokens am Stück
Der 256k-Context ist die zweite Schlagzeile. Damit fütterst du komplette Codebases, lange juristische Verträge oder einen Tag Slack-Logs am Stück und bekommst zusammenhängende Antworten. Llama 4 Scout schafft offiziell zwar mehr, fällt aber bei langem Context spürbar ab – Small 4 hält die Substanz.
EXTRA-TIPP: vLLM macht es flott
Auf zwei H100-80GB kommst du mit vLLM 0.6+ auf rund 90 Tokens pro Sekunde im FP8-Mode. Das reicht für interaktive Chat-Interfaces – auch im Self-Hosted-Setup. Wer kleiner einsteigen will, nimmt SGLang auf einer einzelnen H100 mit aggressiver Quantisierung.
OPEN SOURCE im echten Sinn
Mistral lizenziert Small 4 unter Apache 2.0 – also auch kommerziell frei. Du darfst das Modell fine-tunen, in eigene Produkte schmieden und auf dem eigenen Server hosten, ohne mit Mistral verhandeln zu müssen. Das ist 2026 leider keine Selbstverständlichkeit mehr: Llama 4 hat eine deutlich engere Lizenz, Qwen mauert beim Coding-Modell.
FAZIT: Pflicht-Download für KI-Self-Hoster
Mit Mistral Small 4 bekommst du ein wirklich offenes Modell, das beim Reasoning, bei Bildern und beim Code mithalten kann. Wer sein KI-Homelab betreibt, lädt sich die Modell-Card auf Hugging Face und probiert es aus – die Lizenz ist freundlich, der Context ist riesig und die Hardware-Anforderungen sind zwar happig, aber machbar.
Häufige Fragen
Was ist neu an Small 4 gegenüber Small 3?
Wie viel VRAM brauche ich daheim?
Welche Lizenz hat das Ding?
Lohnt es sich gegenüber Llama 4 oder Qwen 3.6?
Quellen: Mistral AI Blog, llm-stats.com, Hugging Face Model Card.