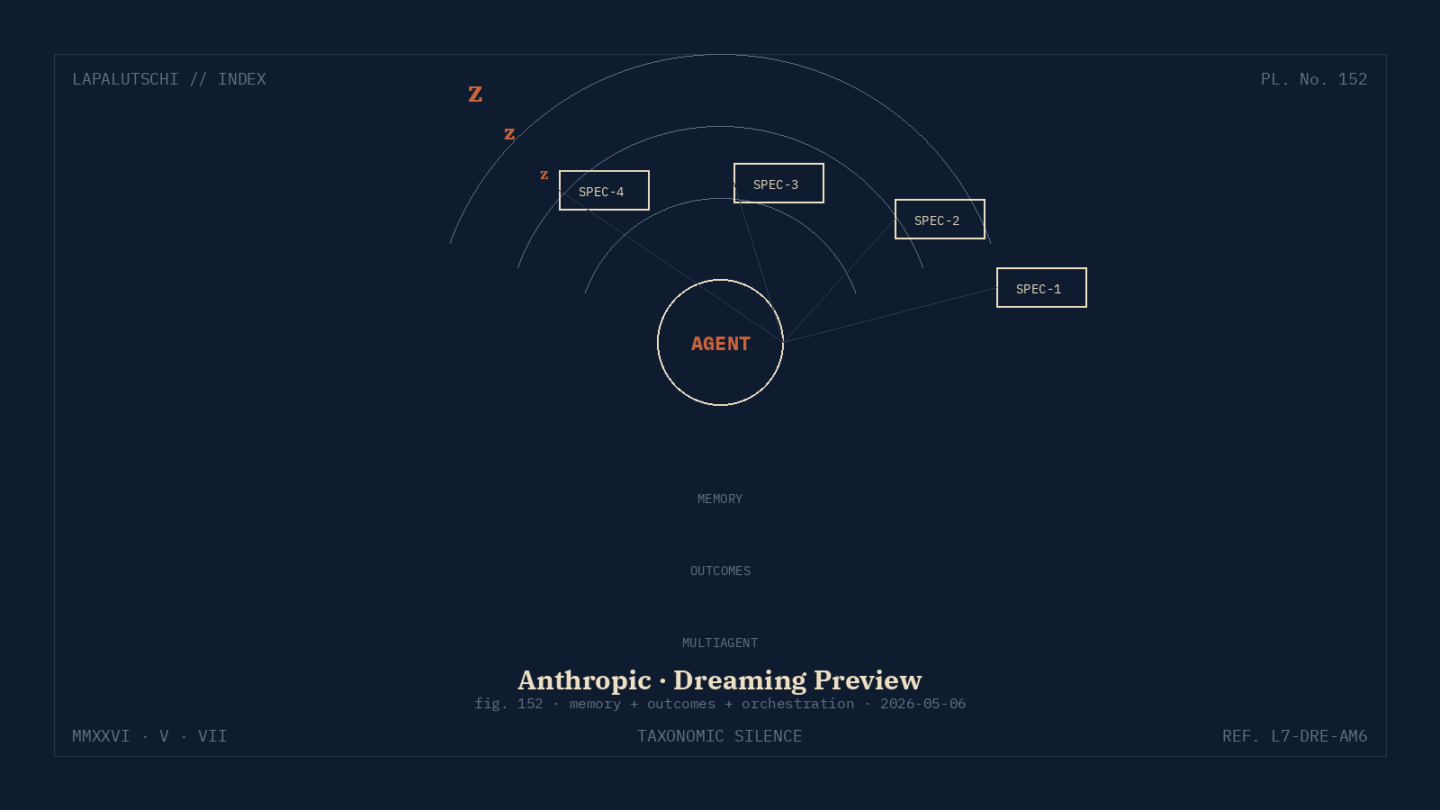
Anthropic hat seine Managed-Agents-Plattform am 6. Mai 2026 mit drei neuen Bausteinen aufgebohrt: Dreaming, Outcomes und Multiagent-Orchestrierung. Das ist kein Marketing-Geblubber, sondern eine echte Architektur-Erweiterung. Agenten merken sich Sessions, lernen aus Mustern, prüfen ihre eigene Arbeit nach Rubric — und können Spezial-Agenten als Untergebene losschicken.
UNGLAUBLICH: Claude darf jetzt träumen
Klingt wie ein Roman, ist aber Code: Dreaming ist ein Hintergrundprozess, der zwischen den Sessions deines Agenten läuft. Er liest die Memory-Files, erkennt wiederkehrende Muster — etwa Fehler, die der Agent öfter macht — und kuratiert daraus neue Notizen. Das nächste Mal, wenn der Agent online geht, liegt eine besser sortierte Wissensbasis bereit.
Anthropic vergleicht es offen mit dem Schlaf bei uns Menschen: das Gehirn räumt nachts auf, sortiert ein, wirft Müll raus. Genau das macht Dreaming für Claude. Aktuell läuft das Feature als Research Preview, also nur für ausgewählte Tester. Aber Anthropic hat klargemacht: Wenn die Telemetrie passt, geht es in die Public Beta.
OUTCOMES: Endlich Note für Note
Wer schon mal einen Agenten auf eine schwammige Aufgabe losgelassen hat, kennt den Frust: Der Output sieht nett aus, ist aber Murks. Outcomes dreht das um. Du schreibst eine Rubric — eine Bewertungsanleitung für den Erfolg — und ein zweiter Grader prüft jede Antwort vor der Auslieferung. Stimmt die Rubric nicht, schickt der Grader die Aufgabe zurück und der Agent macht weiter.
Anthropic-interne Benchmarks zeigen plus 10 Prozentpunkte Erfolgsquote bei harten Aufgaben — auf docx-Generierung sogar +8.4 %, auf pptx-Generierung +10.1 %. Das ist nicht »lustige Studie«, sondern messbarer Effekt.
SCHOCK: Agenten kommandieren Agenten
Der dritte Baustein heißt Multiagent-Orchestrierung. Statt eines Riesen-Modells, das alles selbst macht, schickt ein Lead-Agent kleinere Spezial-Agenten in den Einsatz. Jeder Spec hat eigenes Modell, eigenen Prompt, eigene Tools. Sie arbeiten parallel auf einem geteilten Filesystem und liefern Teil-Ergebnisse zurück.
Klingt nach altem MCP-Multi-Agent-Spielzeug? Ist es nicht. Der Unterschied: Tracebar im Claude Console. Du siehst pro Sub-Agent, was gelaufen ist, welche Tool-Calls passierten, welche Memory-Schreibs. Damit ist endlich Debugging möglich.
So wirst du JETZT Teil der Beta!
Outcomes und Multiagent sind ab sofort als Public Beta auf platform.claude.com freigeschaltet. Du brauchst einen Claude-Platform-Account und einen Managed-Agent. In den Console-Einstellungen aktivierst du die Beta-Toggles — und kannst sofort eine Rubric schreiben oder einen Sub-Agenten registrieren.
Tipp aus dem Anthropic-Devkit: Starte mit einer kleinen Rubric mit drei Kriterien (Genauigkeit, Vollständigkeit, Format) und beobachte, ob der Grader öfter zurückschickt als nötig. Die Latenz pro Loop liegt bei rund 1,5 Sekunden, du merkst also schnell, wenn die Schwellwerte zu streng sind.
EXTRA-TIPP: Memory zuerst, dann Outcomes
Anthropic empfiehlt, Memory (seit April im Beta) als Basis aufzusetzen, bevor Outcomes oder Dreaming dazukommen. Ohne dauerhaften Speicher fehlt den Outcome-Loops das Feedback aus früheren Aufgaben — und Dreaming hätte gar nichts, woraus es Muster ziehen könnte. Erst der Speicher, dann die Bewertung, dann das Träumen.
FAZIT: Endlich erwachsene Agenten
Mit Dreaming, Outcomes und Multiagent-Orchestrierung schließt Anthropic die letzten Lücken zwischen Hobby-Agent und Enterprise-Workflow. Dass Netflix, Rakuten, Wisedocs und Ando schon Pilot fahren, ist ein klares Signal: Wer 2026 Agenten baut, muss diese drei Bausteine kennen. Schau dir die Console an, bau dir eine Rubric, und schalte Memory scharf — dann läuft dein Claude bald geordneter als deine eigenen Tasks.